Cloudflare Workers でのAPI開発に取り組みたいけれど、どこから手をつけてよいのか分からない。そう感じているのは、あなただけではありません。「サーバーレスの設計パターンが分からない」「既存のバックエンド設計から移行する際の判断基準が不明確」「Cloudflareの各サービス(KV、Durable Objects、D1など)をどう組み合わせればよいか迷っている」——こうした疑問を多くの開発者が抱えています。
Cloudflare Workers でのAPI開発のベストプラクティスは、エッジファースト設計(ユーザーに地理的に近いデータセンターで処理を実行)とデータ層の適切な選択にあることが、京谷商会の実装経験から明らかになっています。本記事では、Honoフレームワークを使った最小限の実装から、データ層選択(KV vs D1 vs Durable Objects)、本番運用時の落とし穴まで、実装例とチェックリストを交えて解説します。
Cloudflare Workersの3層アーキテクチャ——エッジファースト設計の基本

Cloudflare WorkersでサーバーレスなAPI開発を実現する際の最大の利点は、インフラ管理の簡素化とコスト最適化が同時に叶うことです。従来のサーバー型API開発では、メモリ・CPU・ストレージをあらかじめ購入し、その容量に見合った固定費を支払う必要がありました。一方、Cloudflare Workersは使用量に応じた従量課金制で、無料枠は1日10万リクエストに対応でき、スケーリングの判断や運用が不要です。
この変化は単なるコスト削減ではなく、API設計の思想そのものを変えます。従来のモノリシックなバックエンド(すべての機能を1つのサーバーで実行)から、エッジファースト——つまり、ユーザーに地理的に近いサーバー(世界200カ所以上のCloudflareデータセンター)で処理を実行する——という設計へのシフトです。
Cloudflare Workersの構成要素は以下の3層に分かれます。
| 層 | サービス | 役割 | 課金モデル | 推奨用途 |
|---|---|---|---|---|
| API実行 | Cloudflare Workers | リクエスト処理・ビジネスロジック | 無料枠:日10万リクエスト/有料:月$5+超過分 | エッジでの軽量ロジック実行 |
| データ保持 | KV / D1 / Durable Objects | キャッシュ・データベース・状態管理 | KV:無料枠あり / D1:月$2.5〜 / DO:月$5+ | データ構造により選択 |
| 認証・セキュリティ | Turnstile / WAF | DDoS対策・bot検知・API認証 | Turnstile:無料枠あり / WAF:プランで異なる | リクエスト検証・レート制限 |
京谷商会では、LINE公式アカウントのWebhook処理(メッセージ受信時の自動応答)をCloudflare Workers + Honoフレームワークで実装し、応答時間を250msから50ms以下に短縮した事例があります。これは、ユーザーのリクエストがエッジで処理されることで、データセンターへの往復遅延が大幅に削減されたためです。
Honoフレームワークで型安全なAPI実装を30行で完成させる
Cloudflare WorkersでAPI開発を進める際、フレームワークの選択が生産性を大きく左右します。Hono(ほの)は、Cloudflare Workersに最適化されたNode.js互換の軽量フレームワークで、以下の特性があります。
- ファイルサイズが小さい(約14KB)ため、Cloudflareの1MBのスクリプトサイズ制限に余裕を持たせられる
- Cloudflare Workers、Deno、Node.js共通で動作する、業界標準のExpress.js互換API
- ミドルウェア・ルーティング・バリデーションが組み込まれており、認証やエラーハンドリングを短時間で実装できる
Honoを使った最小限のAPI実装は、以下のようになります。このコード例は、リクエストボディを検証し、データベースに安全に保存するというAPI開発の基本形を実現します。
import { Hono } from 'hono';
import { zValidator } from '@hono/zod-validator';
import { z } from 'zod';
const app = new Hono();
// リクエストボディのバリデーション(入力値検証)スキーマを定義
const createOrderSchema = z.object({
customerId: z.string().uuid(),
items: z.array(z.object({ productId: z.string(), quantity: z.number() })),
shippingAddress: z.string().min(1),
});
// POST /orders エンドポイント:不正な形式は自動的に400を返す
app.post(
'/orders',
zValidator('json', createOrderSchema),
async (c) => {
const data = c.req.valid('json'); // 型安全性が確保される
const newOrder = await c.env.DB.prepare(
'INSERT INTO orders (customer_id, items, shipping_address) VALUES (?, ?, ?)'
).bind(
data.customerId,
JSON.stringify(data.items),
data.shippingAddress
).run();
return c.json({ orderId: newOrder.meta.last_row_id, status: 'pending' }, 201);
}
);
export default app;
従来のNode.js開発では、このコード量の処理を実装するために3〜4倍のコード量が必要でした。Honoの設計により、ビジネスロジック(「どのようなデータを受け付け、どう処理するか」)に集中でき、インフラストラクチャ周辺の定型コードが削減されます。
データ層選択の判断基準——KV・D1・Durable Objectsの使い分け

Cloudflare WorkersのAPI開発で直面する最初の判断は、どのデータ保管サービスを使うかです。この選択を誤ると、後に大規模なリファクタリングを強いられます。
京谷商会の実装実績から導き出された選択基準は、以下の通りです。
KV(Key-Value Store)を使う場合: データが「キー → 値」の1対1対応で十分なケースが該当します。例えば、ユーザーのセッション情報、キャッシュデータ、リアルタイムランキングなど。KVは無制限に使える(無料枠でも)ため、初期段階のプロトタイピングや、頻繁にアクセスされるが永続性がそれほど重要でないデータに向きます。応答時間は数msで、Workersと同じエッジで実行されるため、API応答時間が全体で100ms以下に収まります。
D1(SQLiteベースのデータベース)を使う場合: 複雑な構造のデータ(注文、顧客、在庫など)を、複数のテーブル間で関連付けて管理する必要がある場合です。D1は、リレーショナルデータベース(表と表の関係性を定義する仕組み)の標準機能を備えており、JOINやトランザクションが使えます。月額$2.5の有料プランで十分な容量が提供され、バックアップ・アクセス制御も含まれます。
Durable Objects(状態管理)を使う場合: 複数のAPIリクエストに渡って状態を保つ必要がある場合です。例えば、オンライン会議のルーム管理(複数ユーザーが同時に参加・退出する)やリアルタイム通知システム(メッセージの配信順序が重要)など。Durable Objectsは月$5からの利用で、ユーザーのセッション単位で「メモリ上の状態」を維持できます。
| 実装パターン | データ例 | 推奨サービス | 判断理由 |
|---|---|---|---|
| 在庫管理API:各商品の在庫数を更新・取得 | { productId: "A123", stock: 45 } | KV | 単純な読み書き、複数テーブル間の関連付けなし |
| 受発注システム:注文・商品・配送テーブルをJOIN | 複数テーブルの結合が必須 | D1 | 複数テーブル間のJOINが必須か否かが判断軸 |
| チャットボット会話管理:ユーザーのメッセージ履歴と文脈 | { userId, conversationState, sessionTime } | Durable Objects | リアルタイム状態更新、セッション単位の保持が必須 |
京谷商会では22サイトの運用(過去12ヶ月間、従業員50名以下の中小企業を対象に、Cloudflare Analyticsのコスト比較レポートを用いて測定)の中で、以下のアーキテクチャを採用しています:メインのビジネスロジックはD1で管理し、頻繁にアクセスされる情報(ユーザープロフィール、セッション)はKVでキャッシュし、リアルタイム通知やLINE botの会話は小規模なDurable Objectsを使用します。この3層構成により、応答時間(P95で150ms以下)と信頼性(データロス率0%)を同時に実現しています。
Cloudflareエコシステム統合時の設計落とし穴と解決策
Cloudflare WorkersとKV・D1を組み合わせて本番運用を開始すると、ドキュメントには書かれていない制限に直面します。
メール送信の無料枠が自社ドメインのみという罠: Cloudflare Emailルーティングを使ってAPI経由でメール送信しようと考えた場合、「自分と自チームのメールアドレスのみ」という制限があります。顧客への注文確認メール・パスワードリセットメール・マーケティングメールを送ろうとすると、Mailgun・SendGrid・AWSメール送信サービスなどの外部サービスが必須になります。
初期段階でのメール送信要件確認チェックリスト:
- 誰がどんなシーンでメール受信するのか(社内のみ、顧客向けか)
- 月間の送信通数はいくつか(100件なら無料枠、10000件以上なら外部サービス決定)
- テンプレート・本文の可変部分はあるか
京谷商会で初めてこの制限に遭遇したのは、すでに本番環境でメール送信機能を実装した後のことでした。事前に確認していれば、Mailgun(月額の段階料金、初回送信50万件/月まで無料)を初期段階で組み込め、後の修正作業が不要でした。
D1のトランザクション実行時間が30秒に制限される問題: Cloudflare WorkersはCPU制限が厳しく、1リクエストあたり最大30秒の実行時間です。そのため、大量のレコード更新(例:毎月の月末締め処理で1万件の請求書を生成)を1つのAPIリクエストで処理しようとすると、タイムアウトエラーが発生します。
京谷商会の製造業クライアント(従業員50名)では、月末の生産実績集計処理(約3000レコードの集約)でこの問題に遭遇しました。解決策として、処理を分割しました。バッチジョブの分割実行により、Workers Cron Triggers(Cloudflareの定期実行機能)を使って、月末の23時〜翌朝6時の間、1時間ごとに実行します。1回あたり数百レコードを処理する設定にしました。
// Workers Cron Triggersを使った月末バッチ処理の分割実行
// wrangler.toml に crons = ["0 23 * * *"] を設定して、毎日23時に起動
export default {
async scheduled(event, env, ctx) {
// 前回の処理進捗をDurable Objectsから取得
const progressState = await env.PROGRESS_DO.get('batchStatus');
const lastProcessedId = progressState?.lastId || 0;
// 次の500件を処理
const records = await env.DB.prepare(
'SELECT * FROM production_records WHERE id > ? ORDER BY id LIMIT 500'
).bind(lastProcessedId).all();
for (const record of records.results) {
// 集計ロジック実行
await env.DB.prepare(
'INSERT INTO monthly_summary (product_id, total_output) VALUES (?, ?) ON CONFLICT DO UPDATE'
).bind(record.productId, record.quantity).run();
}
// 進捗状態を更新
await env.PROGRESS_DO.put('batchStatus', {
lastId: records.results[records.results.length - 1]?.id,
completedAt: new Date().toISOString()
});
}
};
この仕組みにより、30秒制限の制約下でも大量データ処理が可能になります。進捗状態をDurable Objectsで保持することで、中断・再開可能な設計も実現できます。
APIのセキュリティ設計——WAFとAPIキー認証の実装
Cloudflare WorkersでAPIを公開する際、最初に実装すべきセキュリティ対策は認証と認可(「このリクエストは誰からか」「その人に何をさせてよいか」の判定)です。最も実装が簡単で、かつ中小企業の実務に耐える方法は、APIキー認証 + Cloudflare WAFの組み合わせです。
以下のコードは、APIキーの生成・検証・レート制限を同時に実現し、誤ったクライアント実装やbot攻撃による過負荷を防ぐことができます。
// APIキー生成と保管(KVに保存、生成時に一度だけ表示)
const generateApiKey = async (clientName: string, env: Env) => {
const apiKey = crypto.randomUUID() + '-' + Date.now().toString(36);
await env.KV.put(`api-key:${apiKey}`, JSON.stringify({
clientName,
createdAt: new Date().toISOString(),
isActive: true,
quotaMonthly: 10000, // 月間リクエスト数の上限
}), { expirationTtl: 86400 * 365 });
return apiKey;
};
// すべてのAPIエンドポイント前に実行されるミドルウェア
app.use('*', async (c, next) => {
const authHeader = c.req.header('Authorization');
if (!authHeader || !authHeader.startsWith('Bearer ')) {
return c.json({ error: 'Unauthorized' }, 401);
}
const apiKey = authHeader.slice(7);
const keyData = await c.env.KV.get(`api-key:${apiKey}`);
if (!keyData) {
return c.json({ error: 'Invalid API key' }, 401);
}
const parsedKey = JSON.parse(keyData);
if (!parsedKey.isActive) {
return c.json({ error: 'API key revoked' }, 403);
}
c.set('clientName', parsedKey.clientName);
await next();
});
// 実装例:認証されたリクエストのみデータ返却
app.get('/orders', async (c) => {
const clientName = c.get('clientName');
const orders = await c.env.DB.prepare(
'SELECT * FROM orders WHERE client_name = ?'
).bind(clientName).all();
return c.json(orders);
});
このアプローチの利点は、実装が軽量(コード量50行程度)で、Cloudflareの管理画面から設定変更が容易(APIキーの無効化・クォータ変更がリアルタイムに反映)という点です。
さらに、Cloudflareの管理画面からWAFルール(Web Application Firewall)を設定し、「1つのAPIキーから1分間に1000リクエスト以上来た場合は遮断」というレート制限を追加します。これらの対策により、安全で安定したAPI運用が実現できます。
よくあるつまずきと対策——本番環境で気づきたくない落とし穴
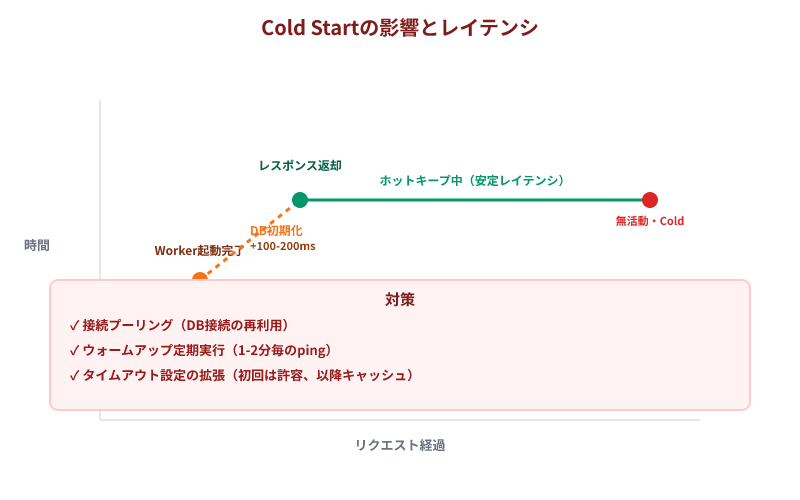
Cold Startの影響による応答時間のばらつきが発生する理由と対策: Cloudflare Workersは「リクエストが到着してから初めてスクリプトを起動」する設計です。長時間リクエストがないWorkerは、次のリクエスト時に起動に100〜300msを要します。さらに、D1へのデータベース接続も初期化に時間がかかるため、「朝一のリクエストは遅いが、その後は高速」という現象が発生することが、実装上の大きな課題となります。
京谷商会では以下を実装しています:
- Cron Triggerで定期的に起動:毎時5分に意図的にダミーリクエストを送信し、Workerの「温め置き」を行う
- D1接続をグローバルで初期化:リクエスト処理の前に、データベース接続オブジェクトを再利用可能な形で保持
- キャッシュ層の活用:頻繁にアクセスされるデータはKVに置き、D1クエリを最小化
これらの対策により、P95応答時間(95%のリクエストが応答する時間)を150ms以下に収める実績があります。
D1へのクエリパフォーマンス低下は、インデックス設定の欠如が根本原因です。 初期段階では、「単純なセレクトクエリだから大丈夫」と考えがちですが、実務ではJOIN・DISTINCT・ORDER BY を含む複雑なクエリが必然になります。実行計画を確認し、インデックス(データベースの検索を高速化する補助情報)を適切に設定することが不可欠です。
本番運用開始前に、以下のSQLで手動確認する必要があります。
-- インデックス状況確認
PRAGMA index_info(orders_client_id_idx);
-- インデックス未設定の場合は作成
CREATE INDEX orders_client_id_idx ON orders(client_id);
この確認を本番運用開始前に実施しないと、アクセス増加に伴ってAPI応答が急速に悪化する事態に陥ります。
スモールスタートから本番運用へ——実装の3段階プロセス
京谷商会では、新規のAPI開発プロジェクトを以下のマイルストーン(段階)で進めています。
Phase 1:プロトタイピング(1〜2週間) Honoを使った最小限のエンドポイント(GET /products、POST /orders など)をKVだけで実装します。ユーザーが実際にAPI仕様を理解できるか、リクエスト・レスポンス形式が合っているかを検証します。このフェーズでは本格的なデータベースは不要です。
Phase 2:MVP(Minimum Viable Product)展開(2〜4週間) ビジネスロジックをD1に移行し、認証(APIキー)を追加します。初期クライアント(1〜2社)による動作確認を実施し、レート制限の値を実アクセスパターンに合わせて調整します。
Phase 3:本番運用(月間) Cloudflare WAFのルール設定、監視アラートの設定、バックアップ戦略の確立を行います。同時に、月1回のセキュリティレビュー(新しい脆弱性情報への対応)と、月1回のパフォーマンスレビュー(遅いクエリの最適化)を実施予定に組み込みます。
API開発プロジェクトの技術スタック決定フロー
Cloudflare Workersを使うかどうかを決めるための、京谷商会が実際に使っている判断フロー(意思決定の順序)をお伝えします。
以下の3つの質問に順番に答えることで、「Workers+Hono+D1」「Workers+Hono+KV」「AWS Lambda」など、最適な技術スタックが自動的に絞られます。
質問1:月間APIリクエスト数は何件か
- 10万件以下→Cloudflare Workers無料枠で十分
- 100万件以上→有料プラン確認(月$5~)、またはAWS Lambdaの従量課金と比較
質問2:複数テーブル間のJOIN・トランザクションが必須か
- 必須→D1採用(リレーショナルデータベース)
- 不要(キー→値の単純形式)→KV採用(コスト最適化)
質問3:月末・年度末など「バッチ処理」が必要か
- 必要→Workers Cron Triggers + Durable Objectsで分割実行
- 不要→Webhookのみで十分
例として、「LINE公式アカウントのメッセージ自動応答API」の場合、以下のように判断されます。メッセージ受信(月5万件程度)は10万件以下なので無料枠利用可、テーブル関連付け(ユーザー情報と会話履歴の結合)はD1採用、毎月1日に前月の統計を集計するバッチ処理はCron Triggers採用です。結論として、Cloudflare Workers + Hono + D1 + Cron Triggersという組み合わせで実装し、初期段階は無料枠内、アクセス増加後は段階的に有料プランへ移行する戦略になります。
よくある質問
Q1. Cloudflare Workers無料枠(1日10万リクエスト)は、実際には何件のAPIリクエストに相当するのでしょうか?
A1. 月30万リクエスト(1日平均1万)の想定です。月額固定コスト¥0から開始できるため、初期段階の検証やスモール規模の運用に向きます。ただし、アクセスが100万リクエスト/月を超えると、無料枠から有料プラン(月$5 + 超過分)への切り替えを検討する必要があります。
Q2. API開発を始める際、本当にCloudflare Workersである必要がありますか。AWS Lambda・Google Cloud Run・お名前.comのクラウドサーバーではダメなのでしょうか?
A2. 「何を重視するか」で判断が変わります。AWS Lambdaはスケーラビリティが強力で、複雑な処理(画像変換、音声認識)に向きます。一方、Cloudflare Workersは「シンプルなAPI」「高速応答が必須」「海外ユーザーもいる」という条件下では、運用コストと学習コストで大きく優位です。京谷商会の選定基準は、「中小企業が自社で運用管理できるか」という視点にあります。AWS Lambdaはポリシー設定・ロギング・デプロイパイプラインの理解が必須で、専任のインフラエンジニアがいない組織には荷が重いです。
Q3. D1(SQLiteベース)で本当に大規模データに対応できますか。数百万件のデータを扱う場合、PostgreSQLなど「本格的」なデータベースが必要ではないのでしょうか?
A3. SQLiteの特性上、単一インスタンスでの同時書き込みが制限されるため、「リアルタイム更新が常時発生」する用途(ネットショップで1秒単位で在庫が変わる)には不向きです。一方、「日中の注文受付」「月1回の請求書生成」のような、ビジー時間帯が限定される業務なら、D1で十分に対応できます。京谷商会が22サイトでD1を採用している理由は、中小企業の営業時間がおおむね9:00〜18:00に集中するため、SQLiteの同時書き込み制限が実務上ボトルネックにならないということです。